innodb_flush_log_at_trx_commit 값이 1인경우 insert 할때 로그파일을 기록한다. 이로인해 초당 몇천건 정도 insert할 내용을 몇십건 정도 insert한다.
show variables like 'innodb_flush_log_at_trx_commit';
DB dump파일을 import 할때는 로그가 요 없으므로 0 으로 설정하고 변경 값 확인후 insert한 다음 추후 설정값을 다시 복구한다.
set global innodb_flush_log_at_trx_commit=0;
3. table 별로 백업 sql 만들기
db_root_pw='비밀번호'
db_list=`echo "show databases;" | mysql -N -uroot -p"$db_root_pw"` for db in $db_list ;do table_list=`echo "show tables" | mysql -N -uroot -p"$db_root_pw" $db` for table in $table_list ; do mysqldump -uroot -p"$db_root_pw" $db $table > $db.${table}.sql done done
4. 옵션을 통해 시간 줄이기
--no-autocommit=1 : autocommit을 끄고 개의 테이블 입력 완료후 commit 수행, 오류 발생시 다시 처음부터 시작함
--single-transaction=1 : 작업 후에 변경 된 데이터의 내역을 다시 적용하지 않는다.
mysql -hHOST_NAME -uMY_ID -pMY_PASSWORD --database DB_NAME < DUMP.sql
5. txt 파일이용하기
- export 할때
mysqldump DATABASE_NAME > DUMP.txt
- import 할때
mysql -u username -p –database=DATABASE_NAME < DUMP.txt
6. large dump
mysql -h localhost -uroot -pPASSWORD set global net_buffer_length=1000000; set global max_allowed_packet=1000000000; SET foreign_key_checks = 0; SET UNIQUE_CHECKS = 0; SET AUTOCOMMIT = 0; source /media/dbdump.sql
완료후
SET foreign_key_checks = 1; SET UNIQUE_CHECKS = 1; SET AUTOCOMMIT = 1;
7. 기타
my.cnf 위치찾기
mysql --verbose --help | grep -A 1 'Default options'
--no-autocommit=1 일단 autocommit을 끄고, 1개의 테이블 입력이 완료될 때 까지 기다렸다가 commit을 수행 한다. 요거이 좋다!!! 대신 뻑나면, 다시 첨부터~~~ 우어!!!
--single-transaction=1 작업 후에 변경 된 데이터의 내역을 다시 적용하지 않는다. 즉, 중간에 값이 바뀌질 않는다면 가능하다는 말씀.
--extended-insert=1 요거이 관건인데, 쓸데 없이 INSERT 구문이 늘어나는 것을 막아준다. 가령 ->INSERT INTO `A` VALUES (1,10),(2,20); 이러면 될 것을 , -> INSERT INTO `A` VALUES (1,10); -> INSERT INTO `A` VALUES (2,20); 으로 늘려준다. 이러면 하루 온 종일 도는 거다 --;;
이 3가지 옵션으로 백업을 한결과.... 놀라움을 극치 못했습니다 연습용 10기가 용량이 육박하는
데이터베이스를 보통 백업을 뜰때 30~40분 정도가 소요됬습니다(서버가 켄츠할배와 같은시기에 나온 제온..)
근데............. 그런데!!!!!!!!!! 저 3가지 옵션을 준후에는 10분 안짝으로 백업이 되는것 입니다..
놀라움을 극치 못하고 그러면 원본 포스팅에서 복원 속도도 체감상 1/10로 줄어들었다는데.......
정말이지 진짜 체감상 1/10로 줄어든 기분입니다.....하~ 이렇게 좋은 옵션이 있을줄은 생각지도 못했네요
일단 대용량 백업을 자주 뜨시는 분들이 계시면 저 옵션도 추천해드리고 실시간 백업을 요하는 분들은
Starting with MySQL 5.6, MySQL instances have a UUID. Cloning servers to quickly create slaves will result in the following error message.
mysql> SHOW SLAVE STATUSG ... Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work. ...
The solution is simple. Clear our the file based configuration file (located in the MySQL datadir) and restart the MySQL instance.
$ rm -f /mysql/data/auto.cnf $ service mysql restart
#MYsql 리플리케이션이란? # Replication은 3.23.15부터 지원되기 시작한 기능으로 ‘복제’라는 사전적 의미에 맞게 마스터의 MySQL 서버의 데이터를 여러 대의 슬레이브 MySQL 서버의 데이터와 동기화 시켜주는 기능이다. 주로, MySQL의 데이터를 실시간으로 백업하거나, 데이터 서버의 부하분산을 하고자 할 때 많이 사용된다.
0. 서버 설정
1번서버 - master 서버 : 1차네임서버 : 192.168.1.111 2번서버 - slave 서버 : 2차네임서버 : 192.168.1.222
mysql 버전은모두 mysql 5.X 이다. 두 서버 모두 mysql 데이터는 /free/mysql_data 에 위치해 있다고 가정한다.
1. Master 서버 설정
# vi /etc/my.cnf
(1) my.cnf 파일에서#log-bin=mysql-bin 부분의 주석을 반드시 해제해준다 슬레이브 서버에서 저 바이너리 로그를 기준으로 데이터 리플리케이션을 실행 하기 때문에 저 로그파일이 꼭 필요하다!
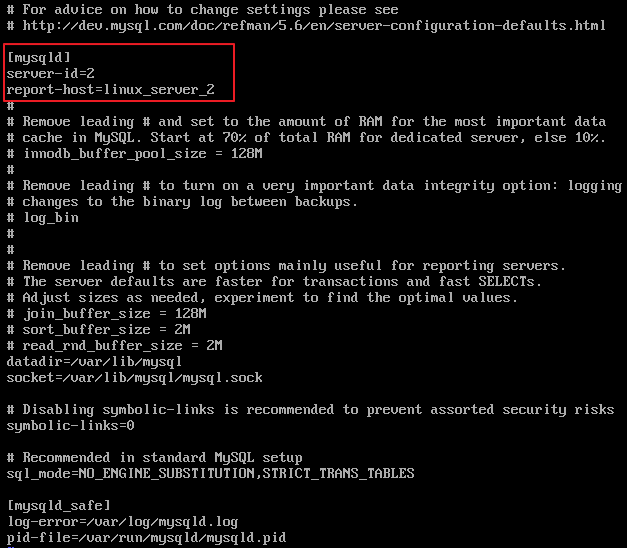
(2) server-id = 1 로 설정한다. 마스터서버와 슬레이브서버의 번호가 서로 다르기만 하면 되기 때문에 원하는 번호를 지정한다.
(3) slave 서버 에서 접속 할 수 있는 Mysql 계정을 생성해준다 # mysql -u root -p 로 디비 접속 mysql > GRANT REPLICATION SLAVE ON *.* TO 유저명@접속허용할IP IDENTIFIED BY '패스워드';
접속허용할 IP에 특정 IP만을 부여 할 수도 있고 '%' 를 적어주면 모든 외부의 접속을 허용한다는 의미이다. mysql > use mysql mysql > select * from user \G; 명령로 설정이 되어 있는지 확인 할 수 있다.
아래 셋팅은 실제 마스터 서버인 1차네임서버 서버의 설정 내용이다.
접속을 허용한 유저 이름은 : nayana nayana의접속을 허용한 IP : 192.168.1.222 (2차 네임서버)
슬레이브 서버(192.168.1.222) 에서 nayana 라는 계정의 Replication 접속을 허용한 것을 볼 수 있다.
(4) mysql을 재시작 하고 마스터 서버의 동작을 확인한다. "mysql-bin.000022" 라는 바이너리 로그 파일을 생성한 것을 볼 수 있다.
2. Slave 서버 설정 (1) 마스터 서버의 DB를 슬레이브 서버의 DB에 복사한다!(= 최초1회는 직접 복사해서 동기화해준다!) 이유는?
mysql 리플리케이션은 rsync와 다르게동기화로 엮여진시점부터의 DB변화를 동기화 시킨다.
[ 동기화 전 DB 구조] 마스터슬레이브 1 1 2 2 3
########## 동기화 후 마스터 서버에 4 라는 DB를 추가하면? #########
[ 동기화후 DB 구조] 마스터슬레이브 1 1 2 2 3 4 4
이렇게 4 라는 DB만 추가되고 3이라는 DB는 추가되지 않는다. 애초에 처음부터 DB내용이 달랐기 때문! rsync 였다면 양쪽에 모두 똑같아 졌을 것이다.
[ 마스터 서버 ] # cd /free # tar zcvf mysql.tar.gz mysql_data # sz mysql.tar.gz
압축한 파일을 다운받아 슬레이브 서버의 /free/mysql_data 디렉토리에 플어준다. 이로서 최초 동기화를 완료했다.
(2) /etc/my.cnf 파일을 수정한다! 57 , 62 번 라인은 주석처리해주고 98번 라인부터는 아래와 같이 주석을 풀고 마스터 서버에 접속할 정보를 적는다.
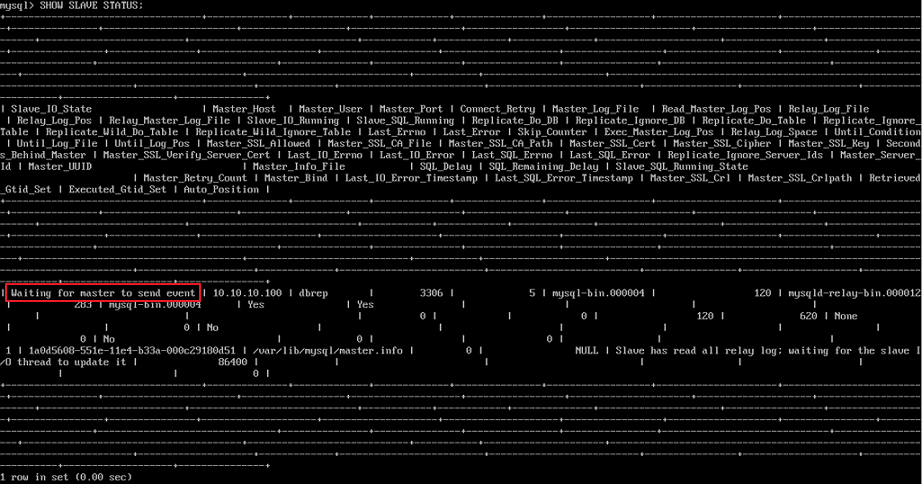
(3) mysql 을 재시작 한후 mysql에 접속하여 동기화가 되었는지 확인한다. 동기화가 정상적으로 되었다면 아래와 같이 "Waiting for master to send event" 라는 구문이 출력된다!
이제 마스터 서버에서 DB를 생성하거나 삭제하면 슬레이브 서버에서도 똑같이 동기화가 될 것이다!! 올레~!
서론 응용 프로그램 혹은 웹 페이지의 작은 기능 단위 연동을 위해서는, rsync로 db 파일을 동기화하는 경우가 있었다. 하지만 rsync 서비스도 정상인지 봐야 하고 스케줄링(crontab) 주기도 설정해야 하고 간혹 문제가 생기기도 하고 테이블 index가 꼬이거나 파일이 깨지는 등 번거로운 방법이다.
그래서 향후에는 작은 부분이더라도 Replication을 하기로 했다. 특정 DB 혹은 특정 Table만 동기화 설정이 가능하기 때문이다.
선행 작업
Master에서 Slave로 동기화하기를 원하는 DB(및 Table)은 미리 Dump를 떠서 최초 1번은 Slave에 생성해 놓아야 한다.
Master 서버 설정
우선 server-id가 1로 설정되어 있는지 확인한다.
Master는 보통 1로 설정한다. 그래야 Slave에서 부가적인 설정을 할 필요가 없다.
Master에서 메모한 2개의 값을 MASTER_LOG_FILE 부분과 MASTER_LOG_POS 부분에 대입한다.
Slave가 Master에게서 제대로 동기화 받아오는지 확인해 보자.
mysql> SHOW SLAVE STATUS \G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.xxx.xxx ...(생략)...
Waiting for master to send event 문구가 표시되면 정상이다.
여기서 일단 끝인데... 조금 더 세부적으로...
모든 DB를 동기화하는 것이 아니라, 특정 DB 특정 Table만 동기화 하고 싶다면 아래와 같이 my.cnf 파일에 설정한다.