MySQL Replication을 이용하여 DBMS 단방향 이중화하기
웹서버 부하로 인해 L4를 이용하여 로드밸런싱으로 웹서버의 부하를 해결하였지만, DB 서버의 부하로 인하여 사이트가 느리게 열리는 현상이 발생하게 되었습니다
DB 서버를 이중화하는 방법은 없을까 하여 찾아보니 MySQL의 리플리케이션이라는 기능이 있더군요 이 기능을 이용하면 DB를 이중화 할 수 있는다는 것을 알게 되었습니다
이번 포스팅에서는 MySQL의 리플리케이션은 무엇이고, 리플리케이션을 이용한 DB를 이중화하는 방법을 알아보도록 하겠습니다.
| MySQL Replication(복제)란? |
리플리케이션(Replication)은 복제를 뜻하며 2대 이상의 DBMS를 나눠서 데이터를 저장하는 방식이며, 사용하기 위한 최소 구성은 Master / Slave 구성을 하여야 됩니다.
Master DBMS 역할 :
웹서버로 부터 데이터 등록/수정/삭제 요청시 바이너리로그(Binarylog)를 생성하여 Slave 서버로 전달하게 됩니다
(웹서버로 부터 요청한 데이터 등록/수정/삭제 기능을 하는 DBMS로 많이 사용됩니다)
Slave DBMS 역할 :
Master DBMS로 부터 전달받은 바이너리로그(Binarylog)를 데이터로 반영하게 됩니다
(웹서버로 부터 요청을 통해 데이터를 불러오는 DBMS로 많이 사용됩니다)
| MySQL Replication(복제) 사용목적 |
MySQL 리플리케션(Replication)은 사용목적은 크게 실시간 Data 백업과 여러대의 DB서버의 부하를 분산 시킬수 있습니다
1, 데이터의 백업
예로 Master 서버를 데이터의 원본서버, Slave서버를 백업서버로 지칭하겠습니다
먼저 Master 서버에 DBMS의 등록/수정/업데이터가 생기는 즉시 Slave 서버의 변경된 데이터를 전달하게 됩니다 이러한 과정으로 데이터의 백업을 할수 있으며, 또한 Master 서버의 장애가 생겼을 경우 Slave 서버로 변경하여 사용할수 있습니다.
그림으로 표현한다면 먼저 사용자가 사용하는데 발생하는 쿼리를 Master 서버에 요청하며, Master 서버의 발생된 쿼리를 Slave 서버로 전달하게되어 백업의 용도로 사용할수 있습니다
2. DBMS의 부화분산
사용자의 폭주로 인해 1대의 DB서버로 감당할수 없을때, MySQL 리플리케이션(Replication)을 이용하여 같은 DB 데이터를 여러대를 만들수 있기에 부하를 분산하수 있습니다
그림으로 표현한다면 Master 서버를 등록/수정/삭제를 사용하는 서버로 사용하고, Slave 서버를 데이터를 읽는용도로 사용하게 되면 DBMS의 부하를 분산하는 용도로 사용할 수 있게 됩니다
| MySQL Replication 주의사항 |
MySQL Replication을 사용시 다음과 같은 주의하여야 될 사항들이 있습니다 반드시 필독 후 하시고 진행하시기 바랍니다.
1. 호환성을 위해 Replication을 사용하는 MySQL의 동일하게 맞추는것이 좋습니다
2. Replication을 사용하기에 MySQL 버전이 다른 경우 Slave 서버가 상위 버전 이여야 합니다
3. Replication을 가동시에 Master 서버, Slave 순으로 가동시켜야 합니다
| MySQL Replication 구성하기 |
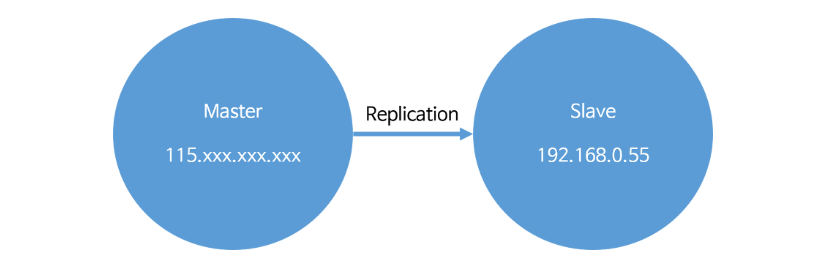
이번 리플리케이션 포스팅에서는 2대의 DBMS를 이용하여 등록/수정/삭제를 하는 Master 서버와 Select 를 사용하는 Slave 서버로 하겠으며, 구성은 다음과 같습니다
위 그림과 같이 웹서버에서 데이터 등록/수정/삭제는 Master 서버로 구성하고, 데이터를 읽을경우 Slave 서버로 구성하여 MySQL DBMS를 이중화 하도록 하겠습니다.
| MySQL Replication 설정하기 - (Master 서버) |
이제 MySQL Replication을 설정 해보도록 하겠으며, 먼저 Master 서버의 설정부터 하겠습니다
MySQL 리플리케이션을 사용하기 위해선 먼저 DB, 계정, 리플리케이션 계정을 생성하여 됩니다
구성정보는 아래와 같이 하겠습니다.
[Master 서버 DB, 계정정보]
IP : 192.168.65.148(Master), 192.168.65.149(Slave)
DadaBases : repl_db
ID : user1
PW : test123
[Replication 계정 정보]
IP : 192.168.65.148 - (Master)
ID : repl_user
PW : test456
- Master 서버에 데이터를 Slave 서버로 복제하기 위해선 MySQL 계정이 필요합니다
- MySQL root 계정으로 사용하는것은 보안상 좋지 않기 때문에 복제계정을 생성하는것이 좋습니다
1. MySQL DB, 계정생성 및 권한설정
1) DB 생성
| 1 | mysql> create database repl_db default character set utf8; |
2) 계정생성
| 1 | mysql> create user user1@'%' identified by 'test123'; |
3) 권한부여
| 1 | mysql> grant all privileges on repl_db.* to user1@'%' identified by 'test123'; |
2. 리플리케이션 계정생성
| 1 | mysql> grant replication slave on *.* to 'repl_user'@'%' identified by 'test456'; |
3. MySQL 설정 - my.cnf
| 1 2 3 4 |
vi /etc/my.cnf [mysqld] log-bin=mysql-bin server-id=1 |
처음 설치시 위와 같은 설정이되어 있으며, 없다면 새로 추가하시면 됩니다
4. MySQL 재시작
| 1 | # service mysqld restart |
5. Master 서버 정보 확인
| 1 2 3 4 5 6 7 |
mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000010 | 1487 | | | +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec) |
* File : MySQL 로그파일
* Position : 로그 파일내 읽을 위치
* Binlog_Do_DB : 바이너리(Binary)로그 파일(변경된 이벤트 정보가 쌓이는 파일)
* Binlog_Ignore_DB : 복제 제외 정보
| MySQL Replication 설정하기 - (Slave 서버) |
Slave 서버설하기에 앞서 먼저 계정을 생성하겠습니다
MySQL DB, 계정생성 및 권한설정
1) DB 생성
| 1 | mysql> create database repl_db default character set utf8; |
2) 계정생성
| 1 | mysql> create user user1@'%' identified by 'test123'; |
3) 권한부여
| 1 | mysql> grant all privileges on repl_db.* to user1@'%' identified by 'test123'; |
이제 Slave 서버 설정을 하는 방법 2가지 방법이 있습니다
첫번째는 mysql에 들어가서 설정하는 방법과 mysql 설정파일(my.cnf)에서 설정하는 방법이 있으며, 먼저 mysql에서 설정하는 부분부터 알아보도록 하겠습니다
1. MySQL에 접속하여 설정
1) MySQL 설정 - my.cnf
| 1 2 3 4 5 |
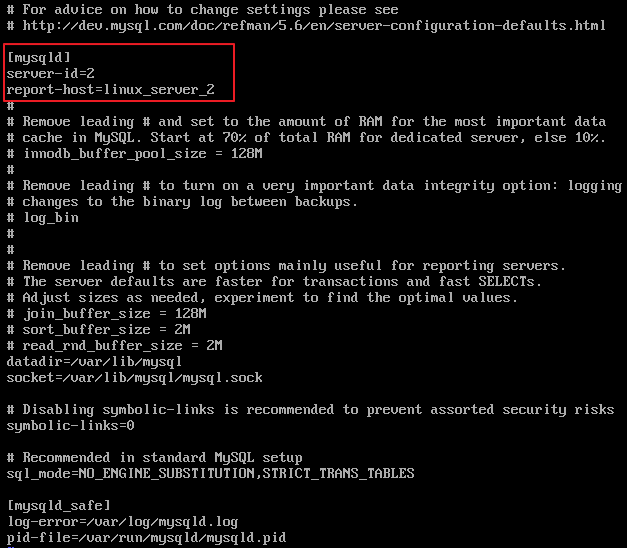
# vi /etc/my.cnf [mysqld] server-id=2 replicate-do-db='repl_db' |
Server-id : Master 서버의 server-id를 제외하고 1~(2^32)-1내의 숫자로 설정하시면 됩니다
replicate-do-db : 복제하고자 하는 데이터베이스를 의미하며 2개이상의 데이터베이스를 할경우 replicate-do-db를 추가하시면 됩니다
2) MySQL 복원
1) Master DBMS에서 복제할 데이터베이스를 dump하여 복원합니다
3) Master 서버로 연결하기 위한 설정
| 1 2 3 4 5 6 |
mysql> change master to master_host='192.168.65.148', master_user='repl_user', master_password='test456', master_log_file='mysql-bin.000010', master_log_pos=1487; |
MASTER_HOST : Mster 서버 IP 입력
MASTER_USER : 리플리케이션 ID
MASTER_PASSWORD : 리플리케이션 PW
MASTER_LOG_FILE : MASTER STATUS 로그파일명
MASTER_LOG_POS : MASTER STATUS에서 position 값
4) MySQL 재시작
| 1 | # service mysqld restart |
2. MySQL에 my.cnf에서 설정하기
1) MySQL 설정 - my.cnf
| 1 2 3 4 5 6 7 |
[mysqld] replicate-do-db='repl_db' master-host=192.168.65.148 master-user=repl_user master-password=test456 master-port=3306 server-id=2 |
replicate-do-db : 복제하고자 하는 데이터베이스를 의미하며 2개이상의 데이터베이스를 할경우 replicate-do-db를 추가하시면 됩니다
master-host : Master 서버의 IP를 입력
master-user : Master 서버에 생성한 리플리케이션(Replication) ID 입력
master-password : Master 서버에 생성한 리플리케이션(Replication) PW 입력
master-port : MySQL에서 사용하는 포트 입력
Server-id : Master 서버의 server-id를 제외하고 1~(2^32)-1내의 숫자로 설정하시면 됩니다
2) MySQL 재시작
| 1 | # service mysqld restart |
| MySQL Replication 상태 확인하기 |
MySQL 리플리케이션(Replication)이 정상적으로 완료되었다면 이제 상태를 확인해야 되겠죠? 다음과 같이 확인하시면 됩니다.
1. Master 서버 상태보기
1) 쓰레드 상태보기
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
mysql> show processlist\G *************************** 1. row *************************** Id: 1 User: repl_user Host: 192.168.65.149:38488 db: NULL Command: Binlog Dump Time: 2434 State: Has sent all binlog to slave; waiting for binlog to be updated Info: NULL *************************** 2. row *************************** Id: 2 User: root Host: localhost db: NULL Command: Query Time: 0 State: NULL Info: show processlist 2 rows in set (0.00 sec) |
Master 서버에서 위 내용과 같이 명령어를 입력하면 Id:1 쓰레드의 Slave서버(192.168.65.149)의 repl_user계정으로 연결되어 있는 것을 확인하실수 있습니다
2. Slave 서버 상태보기
1) 쓰레드 상태보기
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
mysql> show processlist\G; *************************** 1. row *************************** Id: 1 User: system user Host: db: NULL Command: Connect Time: 4294967261 State: Has read all relay log; waiting for the slave I/O thread to update it Info: NULL *************************** 2. row *************************** Id: 2 User: system user Host: db: NULL Command: Connect Time: 90 State: Waiting for master to send event Info: NULL |
쓰레드1(ld: 1)에서는 Master 서버와 통신하기 위한 쓰레드이며, 스레드2(ld: 2)는 업데이트된 내용을 처리하기 위한 SQL 쓰레드 입니다 이러한 2개의 쓰레드에서는 오류가 발생하면 안된다고 합니다.
2) 쓰레드 주요인자 상태보기
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
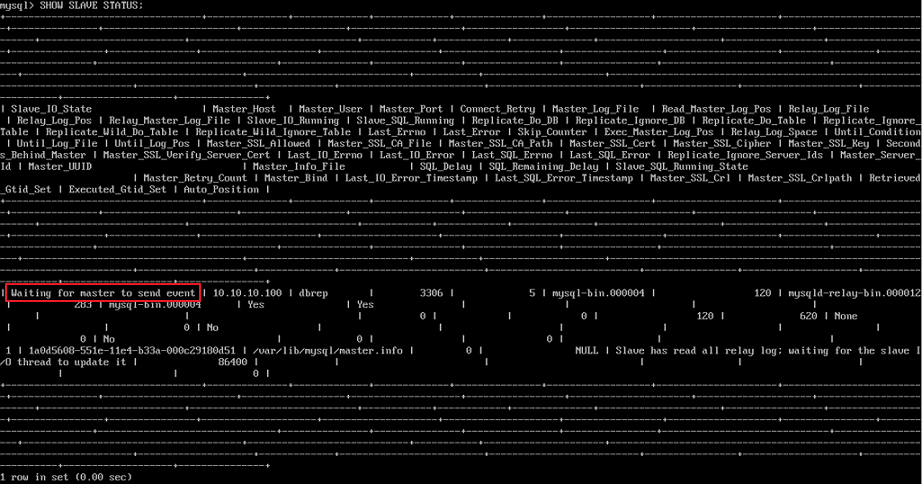
mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.65.148 Master_User: repl_user Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000012 Read_Master_Log_Pos: 434 Relay_Log_File: slave-relay-bin.000042 Relay_Log_Pos: 419 Relay_Master_Log_File: mysql-bin.000012 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: repl_db,repl_db Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 434 Relay_Log_Space: 419 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 1 row in set (0.00 sec) |
Slave_IO_State : Master서버의 연결을 시도하고 Master서버로 부터 이벤트를 기다리며, 재연결하는지에 대해 알려줍니다
Master_Host : 연결된 Master서버 호스트 입니다
Master_User : Master서버 연결하는데 사용되는 사용자 입니다
Master_Port : Master서버 연결하는데 사용되는 포트 입니다
Connect_Retry : --master-connect-retry 옵션의 현재 값 입니다
Master_Log_File : I/O 쓰레드에서 현재 읽고 있는 바이너리 로그파일 이름 입니다
Read_Master_Log_Pos : I/O 쓰레드에서 현재 Master 서버의 바이너리 로그에서 읽은 곳가지의 위치 입니다
Relay_Log_File : SQL 쓰레드에서 현재 relay 로그파일 이름 입니다
Relay_Log_Pos : SQL 쓰레드에 의해 Relay 로그에서 읽고 실행한 곳까지의 위치 입니다
Relay_Master_Log_File : SQL 스레드에 의해 실행된 최근 Master서버의 바이너리 로그 파일의 이름입니다
Slave_IO_Running : I/O 쓰레드가 시작되어 Master서버의 성공적으로 연결되어있는지 여부 여부 입니다
Slave_SQL_Running : SQL 쓰레드가 시작되었는지의 여부 입니다
Replicate_Do_DB : Master서버에서 업데이트된 데이터를 반영될 DB 입니다
Replicate_Ignore_DB : 생략.
Replicate_Do_Table : 생략.
Replicate_Ignore_Table : 생략.
Replicate_Wild_Do_Table : 생략.
Replicate_Wild_Ignore_Table : 생략.
Last_Errno : 가장 최근에 사용된 쿼리의 에러메시지의 번호로 리턴됩니다
Last_Error : 가장 최근에 사용된 쿼리의 에러메시지의 번호로 리턴됩니다
Skip_Counter : 생략.
Exec_Master_Log_Pos : Master서버의 바이너리 로그의 Relay_Master_Log_File로 부터 SQL쓰레드의 의해 마지막 이벤트의 위치 입니다
Relay_Log_Space : 존재하는 모든 Relay 로구우ㅏ 전체 사이즈 입니다
Until_Condition : 생략.
Until_Log_File : 생략.
Until_Log_Pos : 생략.
Master_SSL_Allowed : Master서버에 연결하기 위해 Slave에 의해 사용된 SSL 파라미터 입니다
Master_SSL_CA_File : Master서버에 연결하기 위해 Slave에 의해 사용된 SSL 파라미터 입니다
Master_SSL_CA_Path : Master서버에 연결하기 위해 Slave에 의해 사용된 SSL 파라미터 입니다
Master_SSL_Cert : Master서버에 연결하기 위해 Slave에 의해 사용된 SSL 파라미터 입니다
Master_SSL_Cipher : Master서버에 연결하기 위해 Slave에 의해 사용된 SSL 파라미터 입니다
Master_SSL_Key : Master서버에 연결하기 위해 Slave에 의해 사용된 SSL 파라미터 입니다
Seconds_Behind_Master : Master서버에서 실행된 이벤트의 타임스탬프 이후 경과된 시간(초 단위)의 수 입니다
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.65.148 Master_User: repl_user Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000010 Read_Master_Log_Pos: 98 Relay_Log_File: slave-relay-bin.000010 Relay_Log_Pos: 370 Relay_Master_Log_File: mysql-bin.000009 Slave_IO_Running: Yes Slave_SQL_Running: No Replicate_Do_DB: repl_db,repl_db,repl_db,repl_db Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 1007 Last_Error: Error 'Can't create database 'repl_db'; database exists' on query. Default database: 'repl_db'. Query: 'create database repl_db default character set utf8' Skip_Counter: 0 Exec_Master_Log_Pos: 233 Relay_Log_Space: 1123 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL 1 row in set (0.00 sec) ERROR: No query specified |
간혹 위와 같이 에러가 발생하면서 Slave 서버가 작동이 잘안되는 경우가 있습니다
위와 같은 경우는 Slave 서버에 에러가 발생하면 에러가 발생하였던 시점으로 부터Master 서버로 부터 갱신된 쿼리를 실행하지 않게되며, 이경우 에러를 넘겨야 다음 쿼리를 실행하게 됩니다
| 1 2 3 |
vi /etc/my.cnf [mysqld] slave-skip-errors=all |
위와 같은 옵션을 잠시 설정하여 반영하시기 바랍니다. my.cnf에서 설정을 반영하신 후에는 MySQL을 재시작하시기 바랍니다
출처: <http://server-talk.tistory.com/240>
'데이터베이스' 카테고리의 다른 글
| MariaDB Replication(복제) (0) | 2023.11.14 |
|---|---|
| MySQL 복제를 이용한 실시간 백업 (1) | 2023.11.14 |
| mysql 대용량 백업 빠르게하기 (1) | 2023.11.14 |
| mysqldump를 이용한 데이터 이관시 속도 개선 방법 (0) | 2023.11.14 |
| mysqldump 속도 (1) | 2023.11.14 |